Introduccion
Una red bayesiana, o red de creencia, es un modelo probabilístico multivariado que relaciona un conjunto de variables aleatorias mediante un grafo dirigido que indica explícitamente influencia causal. Gracias a su motor de actualización de probabilidades, el Teorema de Bayes, las redes bayesianas son una herramienta extremadamente útil en la estimación de probabilidades ante nuevas evidencias.
Una red bayesiana es un tipo de red causal. Un híbrido de red bayesiana y Teoría de la Utilidad es un diagrama de influencia.
Definicion y concepto
Formalmente, las redes Bayesianas son gráficos acíclicos dirigidos cuyos nodos representan variables y los arcos que los unen codifican dependencias condicionales entre las variables. Los nodos pueden representar cualquier tipo de variable, ya sea un parámetro medible (o medido), una variable latente o una hipótesis. Existen algoritmos que realizan inferencias y aprendizaje basados en redes bayesianas.
Si existe un arco que une un nodo A con otro nodo B, A es denominado un padre de B, y B es llamado un hijo de A. El conjunto de nodos padre de un nodo Xi se denota como padres(Xi). Un gráfico acíclico dirigido es una red Bayesiana relativa a un conjunto de variables si la distribución conjunta de los valores del nodo puede ser escrita como el producto de las distribuciones locales de cada nodo y sus padres:

Si el nodo Xi no tiene padres, su distribución local de probabilidad se toma como incondicional, en otro caso es condicional. Si el valor de un nodo es observable – y por tanto etiquetado como observado, dicho nodo es un nodo de evidencia.
Una red bayesiana consta de dos partes:
– Una cualitativa: un grafo dirigido acíclico
- Un nodo por cada variable del problema
- Un conjunto de enlaces dirigidos sin crear ciclos dirigi
 dos
dos



– Una cuantitativa: una serie de probabilidades condicionadas que determinan una única distribución de probabilidad conjunta.
NODO X
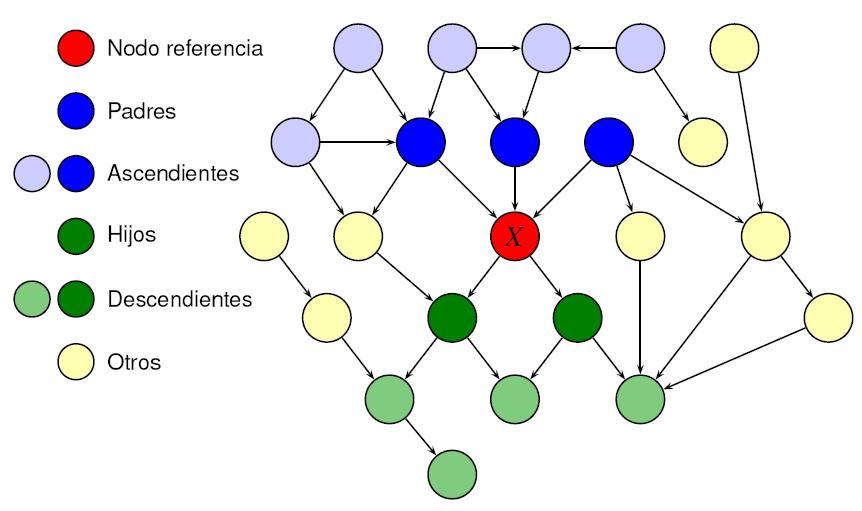
Representación de Independencias
Una red bayesiana representa un conjunto de independencias.
De ellas podemos distinguir:
– Independencias Básicas.- Son aquellas que hay que tener cuidado que se verifquen cuando se construye la red.
– Independencias Totales.- Son todas las que se deducen de las básicas aplicando las propiedades de las relaciones de independencia. Se puede comprobar mediante el llamado criterio de D-separación.
Independencias Basicas

Ejemplos

Aprendizaje Computacional
El aprendizaje es una habilidad de la que disponen gran parte de los sistemas naturales para adaptarse al entorno en el que viven. Es por ello una propiedad interesante de emular de manera artificial, ya que muchos problemas de ingeniería requieren para su correcto funcionamiento algún tipo de adaptación al entorno en el que operan. Definir de manera única y precisa el término «aprendizaje» resulta complicado ya que se puede abordar desde diferentes puntos de vista. A continuación mostramos algunas definiciones posibles que ponen de manifiesto este hecho:
A. «Un proceso por el cual los parámetros libres del sistema se adaptan a través de un proceso continuo de estimulación a partir del entorno en el que el sistema está inmerso«
B. «Aprender significa poder inferir la relación entre X e Y del conjunto de entrenamiento D«
En el contexto de los sistemas artificiales, el aprendizaje, también denominado aprendizaje computacional, se puede entender como:
Un proceso en el que un aprendiz produce una función de aplicación a través de la información de entrenamiento extraída de algún entorno.
Es por lo tanto un fenómeno que sucede a lo largo de un tiempo determinado que puede corresponder a una cierta etapa dentro de la vida del sistema artificial, o por el contrario se puede extender a lo largo de toda la vida de dicho sistema.
Durante este tiempo, el aprendiz (learner) busca en el espacio de todas las posibles soluciones que es capaz de construir1, una solución óptima en relación con alguna medida de costo de la que dispone utilizando para ello recursos computacionales limitados. Es decir, el aprendiz tiene:
1. Un tiempo de búsqueda limitado. Para encontrar una solución el aprendiz debe utilizar un tiempo de CPU que no exceda un tiempo máximo asignado al aprendizaje.
2. Un espacio de búsqueda, o espacio de hipótesis, limitado. Puesto que la solución se debe buscar en un tiempo finito, el espacio de hipótesis debe ser forzosamente restringido para que el aprendiz pueda encontrar una solución antes del tiempo máximo que se ha establecido.
3. Una información limitada acerca del entorno. En la práctica es habitual disponer de escasa información acerca del entorno sobre el que queremos definir una función, ya que p.e no podemos modelarlo analíticamente de forma precisa. Por ello, se deberá buscar una solución acorde con la información disponible en el momento del aprendizaje pero compatible además con aquella información que se pueda extraer del entorno en el futuro.
La búsqueda puede ser ciega o guiada. En el primer caso, no se dispone de ninguna información acerca de en qué sub-espacio puede residir la solución. En cambio, en la búsqueda guiada, el aprendiz si dispone de información concreta de en qué región del espacio de hipótesis ha de buscar la solución. Esta guía permite así restringir la búsqueda a un subespacio, pudiendo resultar útil por dos motivos diferentes:
- Puede eliminar tiempo de aprendizaje ya que se busca en un espacio menor
- Puede hacer posible que la solución obtenida sea más fiable que la resultante de buscar en un subespacio mayor puesto que, dada una información fija acerca del entorno, el aprendiz puede (en general) dar una mejor solución a medida que el espacio de hipótesis es menor.
Existen diversas formas de guiar al aprendiz en un espacio de hipótesis. La primera consistiría en reducir la complejidad del problema a aprender ya que a medida que el problema sea más simple se deberá buscar en un espacio de hipótesis menor. Una segunda posibilidad sería utilizar conocimiento a priori del problema limitando así la búsqueda en aquellos lugares donde se presupone que la solución puede residir.
Criterios para evaluar un sistema aprendizaje.
Los criterios que con mayor frecuencia se utilizan a la hora de evaluar un sistema de aprendizaje son dos:
- la precisión predictiva o generalización
- la comprensibilidad de sus modelos aprendidos
– Generalización.
El objetivo de un sistema que aprende es extraer un modelo representativo a partir del conocimiento disponible de un proceso computacional. Un modelo representativo ha de poder predecir nuevos fenómenos del proceso, y por lo tanto ha de ser capaz de generalizar. Así, la capacidad de generalización de estos sistemas nos da cuenta de lo bien que el modelo obtenido por el aprendiz (en nuestro caso la red neuronal con sus parámetros ajustados) responde a estímulos que el sistema no ha visto a la hora de construir dicho modelo.
– Comprensibilidad.
Si los sistemas de aprendizaje inducen un modelo de un proceso, es deseable que éste sea comprensible, es decir, que sea fácilmente inspeccionado y entendido. Existen diversas razones para ello. Podemos estar interesados en validar el modelo inducido. O bien podemos estar interesados en entender mejor los datos y descubrir las principales características y relaciones entre ellos. O bien podemos estar interesados en modificar ligeramente el modelo para mejorar así la capacidad de generalización. Para cualquiera de estos propósitos se hace necesario poder analizar el modelo construido.
Aplicaciones
En sistemas expertos probabilísticos:
- Representar conocimiento con incertidumbre.
- Después se puede manipular para razonamiento y toma de decisiones.
- Se pueden tratar muchas variables.
- Las reglas (probabilidades) se pueden estimar a partir de datos.
- Los modelos tienen una interpretación clara y bien defnida.
- Actualmente están teniendo un gran desarrollo.
En general las redes bayesianas son un tipo de modelos de minería de datos que pueden ser utilizados en cualquiera de las siguientes actividades de negocio:
- Prevención del fraude
- Prevención del abandono de clientes
- Blanqueo de dinero
- Marketing personalizado
- Mantenimiento preventivo
- Scoring de clientes
- Clasificación de datos estelares
- Deteccion de correo basura


Deja un comentario